DevOps for ML research workflows
Doing machine learning research for the first time? Or perhaps you’ve done this at a large institution and now you’re trying to figure it out on your own? This article is for you!
In recent years, I’ve been working on several projects that require focused and disciplined empirical research. Most of my work is done solo with varying degrees of indirect input from other people. Because of this, I’ve had the opportunity to set up my research workflows completely from scratch.
Because a lot of research is spent running controlled experiments and quickly iterating on ideas, it’s crucial to have an organized and robust research environment. From the many hours I’ve spent (and many mistakes I’ve made), I’ve discovered that improving my research workflow involves asking myself these two questions:
- What can I do to improve my confidence in the results of my work?
- How do I shorten my feedback cycle so that I can iterate faster?
Each of the three ideas presented below answers one or both of the questions above.
Make dev match prod
You’ve been working on a project and it’s been running fine on your laptop. But now it’s time to scale. You might want beefier machines to run on, or you might want more machines to run on, or maybe you just want to play League of Legends while your code runs. Like a normal person, you decide to start running your code on the cloud.

While using a cloud compute provider lets you horizontally and vertically scale your experiments, the tradeoff is that your feedback cycle typically becomes longer. One of the big reasons for this is that you start debugging “it works on my machine” problems almost immediately.
The treatment for this is to make sure your development environment closely matches your “production” environment 1. This shortens your feedback cycle by reducing the number of bugs that happen because of an environment mismatch.
To make your environments match, I suggest creating a Docker image that you can use both on your development machine and in the cloud. Alternatively, you can develop on a dedicated compute instance in the cloud and launch clones of that instance as production machines. You can make this work in GCP and AWS using disk snapshots.
Use a general-purpose deploy script
One of the more unorthodox things that I do in my own setup is that I have a general-purpose deploy script. The goal of the script is to be able to take any shell command you run on your development machine and run it on a production machine.
The script takes two arguments: an identifier job-name and a shell command cmd. It then does the following:
- Writes
<cmd>, plus some other setup commands, to a file in my working directory calledrun.sh. - Bundles up my current working directory (which contains all of my scripts and code) into a file called
<job-name>.zip. - Uploads
<job-name>.zipto the cloud. - Spins up an instance which a) downloads and unzips
<job-name>.zip, b) executesrun.sh, and c) shuts itself down.
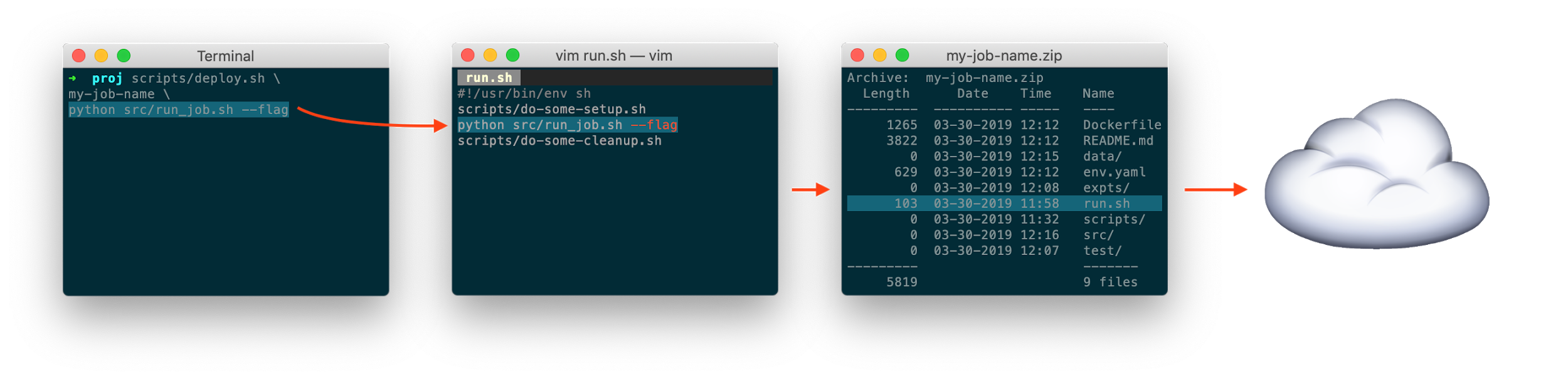
This has two main benefits:
- I can be certain that the exact code that was running on my development machine is now running in production. This reduces the occurrence of bugs and lets me iterate faster.
- For greater reproducibility, I can now audit and re-run any code that has ever run on a production machine. This increases confidence in my results.
Dealing with data
Many machine learning workflows (e.g. anything involving supervised learning) also involve reading from large datasets. To keep your datasets in sync between your development and production environment, there are a few things you can do:
- Include data in your working directory. This doesn’t work well if you have a lot of data, because you will have to upload the data as part of your job for each deploy.
- Maintain separate separate copies of the data on every machine. This works okay if your data doesn’t change often, but is painful if your data does change often. Every time your data changes, you will need to update your Docker image or your disk snapshot.
- Store data in an object store (e.g. S3) and download it at the beginning of every job. This works pretty well if the execution time of your job is not dominated by the initial data transfer.
- Synchronize data between dev and prod machines using NFS. This is an excellent alternative if you do not want to write S3 client code for accessing files.
The next section discusses the last two choices and explains why I prefer the latter.
Use NFS for storing data
For a personal project, I was using GCS (GCP’s S3 equivalent) to store my data for a while. There are a lot of benefits to using GCS:
- Storage is cheap
- You can store petabytes of data with no increase in latency
- You can easily share data with others by sending them a URL
- You can access GCS from anywhere
Unfortunately, GCS lacks the ease of use of a filesystem. This manifests in a few ways 2:
- Navigating files and directories is a pain. Operations like “counting the number of files in a directory” are extremely easy with a filesystem but frustratingly hard in GCS. (This is because GCS has no native notion of directory structures.)
- It’s clunky to write code for. Any operation involving data requires interfacing with the GCS client library or the
gsutilcommand line tool. - Large files might present a problem. GCS supports streaming files piece by piece, but if your research code does not, you will need to first download the whole file to your local system.
My research workflow is very well suited to using a filesystem as opposed to an object store like GCS, so I bit the bullet and set up an NFS server on GCP. After that, I configured my Docker instances and Kubernetes cluster to mount the NFS server on startup.
After switching to NFS, operations that used to look like this:
def load_model_state_from_path(path):
fd, name = get_tmp_filename()
logger.info('Downloading %s -> %s', path, name)
blob = get_blob(path)
with os.fdopen(fd, 'w') as ofd:
blob.download_to_file(ofd)
rv = torch.load(name)
os.unlink(name)
return rv
now look like this:
def load_model_state_from_path(path):
return torch.load(path)
The ease I’ve gained in writing new code makes it easier to iterate quickly. With a little bit of discipline about how you handle data files (e.g. use a versioning scheme, avoid overwriting data) you can also develop confidence in your results.
Setting up NFS
So… how do I set up NFS in my workflow? You have two main options:
- Use a turnkey solution. This would be EFS on AWS or Cloud Filestore on GCP. This solution is easy to set up but costs a lot to maintain (storage will cost around $0.20 – $0.30 / GB / month).
- Roll your own NFS server. This solution is best if you are cost conscious. On GCP, the cost of setting up your own NFS server is:
- $0.04 / GB / month (an 80% savings over Cloud Filestore), plus
- about $50 / month in overhead (to run the compute instance that powers the NFS server)
On GCP, at least, it’s pretty easy to set up a single node file server.
Once you have NFS up and running, you’ll need to connect it to your dev and prod machines.
- If you are running Kubernetes on GCP (i.e. Google Kubernetes Engine), this guide has everything you need to mount your NFS onto your pods.
- If you are launching jobs on bare compute instances (and are on Linux), you’ll need to edit your
/etc/fstabfile to mount your NFS onto the instances. Here’s a guide on how to do that.- This other guide is specific to AWS and will help you mount EFS onto your EC2 instances.
Send emails to yourself
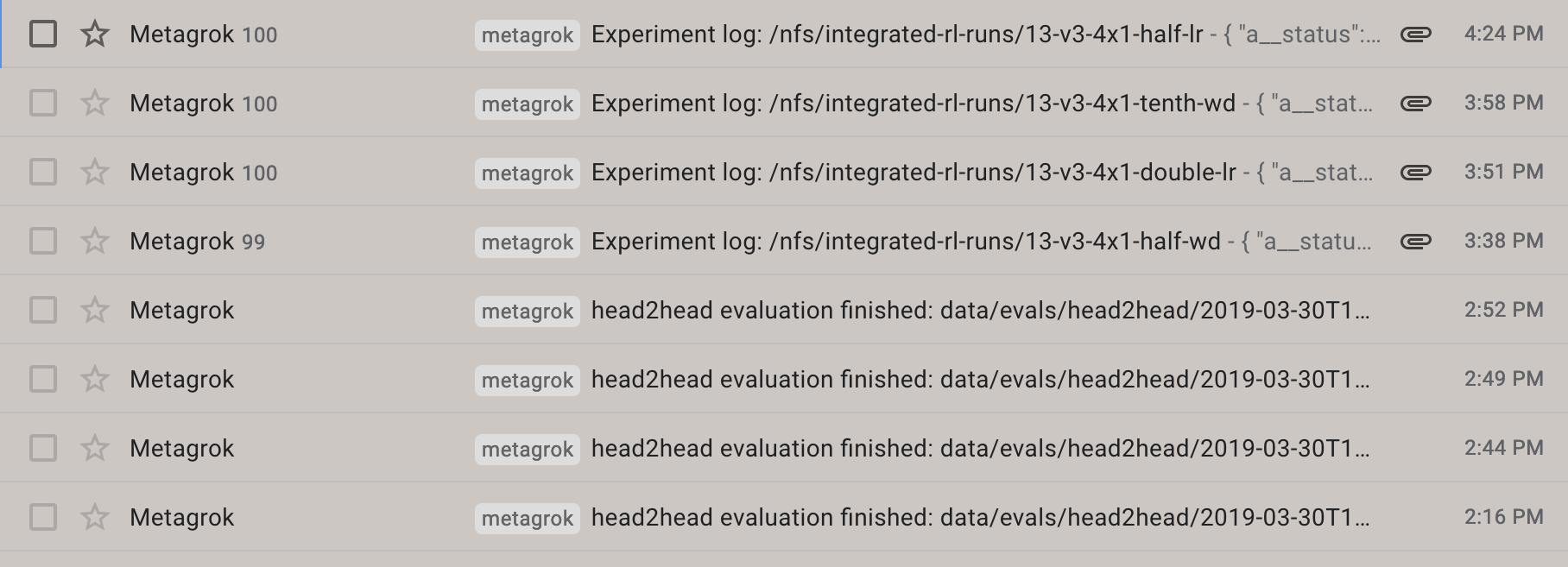
When checking up on my experiments in the past, I would either:
- obsessively refresh the GCP dashboards and thus waste time, or
- forget about my experiment for days (and sometimes even weeks).
My solution to this one is pretty simple: I have my jobs send me emails whenever they reached a satisfactory checkpoint (such as completing an iteration of training, for example). This makes my feedback cycle as short as possible without me having to spend any time checking up on my experiments.
You can take it one step further by putting useful information into the email. For a while I was generating loss curves by hand whenever an experiment finished. To make things easier on myself, I now have my jobs programmatically generate loss curves and attach them to my emails.
Of course, email notifications can end up being counterproductive if you send too many of them. To reduce the amount of clutter in your inbox, I follow these two guidelines:
- Bias toward sending too few emails as opposed to too many emails.
- When it makes sense, take advantage of your email client’s conversation threading feature by sending emails to yourself with the same subject line.
For personal projects, I’d recommend Mailgun. Integration into your code is dead simple, and it’s also 100% free if you send less than 10,000 emails per month.
Final words
While I think I’ve improved a lot over the last few years, I still think I have a lot to learn. I’d love to hear your thoughts about these tips, or ideas for what your own environment looks like!
Thanks to @nodira and Zack for reading earlier drafts of this post.
Footnotes
-
Here I am abusing the development environment vs production environment terminology. My development environment is where I edit and test my code; usually it’s my laptop or a dedicated compute instance that I manually launch. My production environment is where code runs without modification; it’s usually a compute instance that is launched programmatically. ↩
-
The pain points here describe GCS, but generally apply to a lot of storage systems, like HDFS or any type of database. While I’d hesitate to say that “filesystems” are the ultimate way to navigate and store data with ease, I do think that most computer-literate people are exposed to filesystems early on in their computer usage and it ends up being a very familiar way to do business. ↩